






 and How Data Passes Through Them")



, and Neural Networks in a structured way")
")
 That You’ll Want to Buy for yourself")





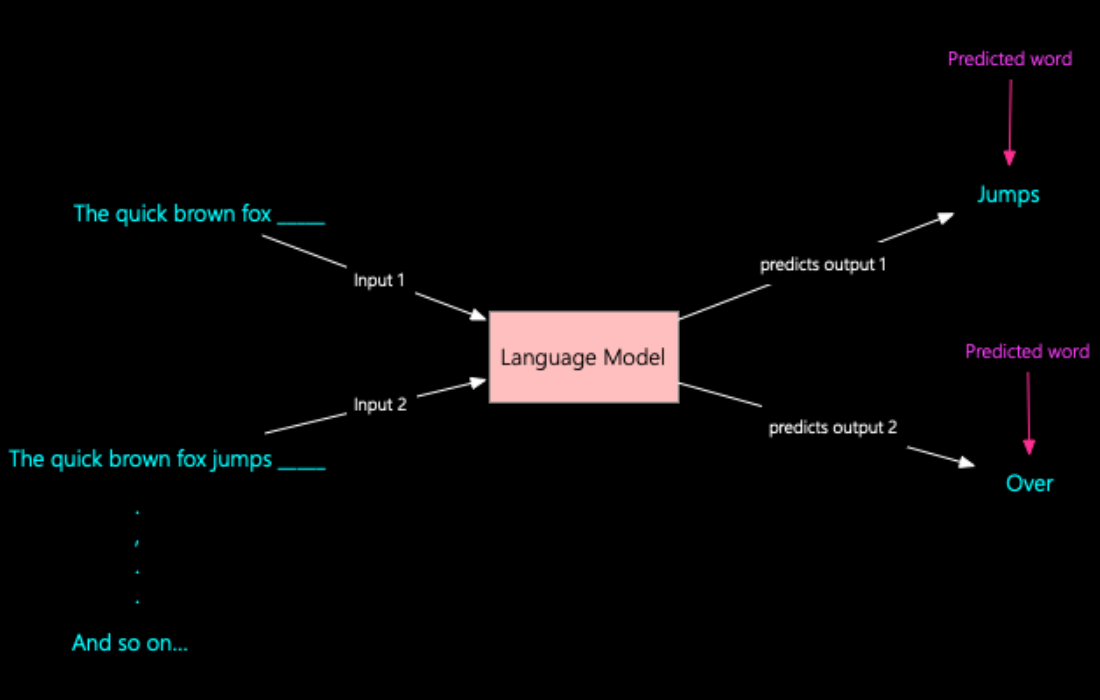
Large Language Models (LLMs) such as GPT (Generative Pre-trained Transformer) are a class of deep learning models that have revolutionized natural language processing (NLP). They are based on the Transformer architecture, which is highly effective at processing and generating human-like text. One of the most fascinating aspects of these models is how data passes through their intricate layers, ultimately enabling them to generate meaningful responses or perform tasks like translation, summarization, and more.
In this blog, we’ll explore the layers of LLMs and how data moves through them, providing a clear understanding of how these models process and generate text.
1. Overview of Transformer Architecture
At the heart of most modern LLMs is the Transformer architecture, which was introduced in the seminal paper “Attention is All You Need” by Vaswani et al. in 2017. The Transformer model consists of two main components: the Encoder and the Decoder. However, in the case of models like GPT, the focus is on the Decoder portion of the Transformer.
The Transformer uses layers of attention mechanisms, known as Self-Attention, to process input sequences. These layers allow the model to weigh the importance of different words in a sentence, regardless of their position, enabling it to better understand the context and relationships within the text.
2. Key Layers in LLMs
LLMs like GPT-3 and GPT-4 consist of multiple layers stacked on top of one another. Each layer has a specific role in processing the input data and refining the model’s understanding of the text. Let’s break down the key layers involved in LLMs and how they function:
a. Input Embedding Layer
The first step in processing text data is converting the input words (or tokens) into vectors, which the model can understand. This process is called embedding. Each word is mapped to a high-dimensional vector that captures the semantic meaning of the word in the context of the training data.
For example, the word “cat” might be converted into a vector representation like [0.2, -0.3, 0.5], which encodes its meaning. These embeddings are then passed into the subsequent layers.
b. Positional Encoding
Transformers, unlike RNNs or LSTMs, don’t inherently process sequential data in a step-by-step manner. To allow the model to account for the order of words in a sentence, positional encoding is added to the input embeddings.
Positional encodings are vectors that encode the position of each word within the sequence. For instance, the first word in a sentence will have a different positional encoding than the second, allowing the model to maintain the sequential order of the words. These encodings are added to the word embeddings before they are passed through the layers.
c. Self-Attention Mechanism
One of the key innovations in the Transformer model is self-attention, which allows the model to focus on different parts of the input sequence based on their relevance to each word. Self-attention works by computing a set of query, key, and value vectors for each word in the sequence.
- Query: A vector representing the word we are currently processing.
- Key: A vector representing all the words in the sequence.
- Value: A vector containing the information associated with the key.
The attention mechanism calculates a score that represents how much focus each word should have on every other word in the sequence. This score is used to create a weighted average of all the word vectors (values), effectively allowing the model to decide which words to “pay attention” to when making predictions.
The Scaled Dot-Product Attention mechanism computes these scores as the dot product of the query and key vectors, followed by a scaling factor and a softmax operation to ensure the scores sum to 1.
d. Multi-Head Attention
Instead of using a single attention mechanism, LLMs employ multi-head attention. This allows the model to focus on different aspects of the input data simultaneously. Each “head” in the multi-head attention mechanism performs its own attention operation with different sets of parameters, capturing different types of relationships in the text.
These multiple attention heads are then concatenated and passed through a linear layer to produce the final output of the multi-head attention block.
e. Feed-Forward Neural Network
After the attention mechanism, the output is passed through a feed-forward neural network (FFN). This FFN consists of two linear layers with a non-linear activation function (typically ReLU) in between. The feed-forward network helps further transform the information after it has been processed by attention mechanisms.
Each layer of the LLM has its own FFN, allowing the model to create increasingly complex representations of the input data as it passes through the layers.
f. Layer Normalization
In order to stabilize and speed up training, LLMs use layer normalization after both the attention and feed-forward layers. This technique normalizes the input to each layer by adjusting its mean and variance, ensuring that the gradients during backpropagation remain stable.
Layer normalization helps the model converge faster during training, reducing the chances of training instability.
g. Residual Connections
To prevent the model from losing important information as data passes through multiple layers, residual connections are employed. These connections allow the output of each layer to be added directly to the output of the previous layer, which helps preserve the flow of information and makes training more efficient.
The residual connections also allow the model to learn identity mappings (i.e., no change to the input) if needed, which can be crucial for very deep networks.
h. Output Layer
Finally, after passing through all the layers, the model generates an output. In the case of text generation tasks, this output is typically a probability distribution over the vocabulary, indicating the likelihood of the next word in the sequence. The model selects the word with the highest probability, or in some cases, samples a word based on the distribution, and the process continues iteratively to generate a coherent response.
For tasks like classification or translation, the output layer will be tailored to provide the final result (e.g., class labels or translated text).
3. How Data Passes Through LLM Layers
To summarize the flow of data through these layers:
- Input Data: The raw text is first tokenized and embedded into vectors.
- Positional Encoding: Positional information is added to the word embeddings.
- Self-Attention: The input data is processed through the multi-head self-attention mechanism, allowing the model to focus on relevant parts of the text.
- Feed-Forward Network: The data is transformed by a feed-forward network, adding complexity and learning more abstract representations.
- Layer Normalization and Residual Connections: These ensure stability and efficient learning.
- Output Layer: The final output is generated, typically in the form of a probability distribution for prediction tasks or a sequence of tokens for generative tasks.
This entire process happens multiple times across several layers, with each layer building on the representations learned in the previous one. As data moves through these layers, the model refines its understanding of the input, allowing it to generate highly accurate and contextually relevant text.
Conclusion
Understanding the layers and data flow in LLMs is key to appreciating the complexity and power behind these models. From embedding words to applying multi-head attention and transforming data through feed-forward networks, each layer plays a crucial role in helping LLMs process and generate human-like text. As these models continue to evolve, the sophistication of their architecture and the efficiency of their data flow will only improve, leading to even more impressive applications in fields such as natural language understanding, creative content generation, and more.



