





 and How Data Passes Through Them")



, and Neural Networks in a structured way")
")




")


At its core, ChatGPT-4 is built on the Transformer architecture, which revolutionized AI with its self-attention mechanism. Below, we break down the key components and their roles in generating human-like text.
1. Transformer Architecture Overview
The Transformer consists of encoder and decoder stacks, but GPT-4 is decoder-only (it generates text autoregressively).
Key Layers in Each Block:
1. Self-Attention Mechanism
2. Feedforward Neural Network (FFN)
3. Layer Normalization (Pre-LN or Post-LN)
4. Residual Connections (Skip Connections)
2. Self-Attention Mechanism (The Heart of GPT-4)
Self-attention allows the model to weigh the importance of different words in a sentence dynamically.
How It Works:
1. Input Embeddings
– Words are converted into high-dimensional vectors (d_model = 12288 for GPT-4).
– Positional encodings are added to retain word order.
2. Query (Q), Key (K), Value (V) Matrices
– Each word embedding is projected into Q, K, V via learned weights.
– Q = What the word is “looking for”
– K = What the word “contains”
– V = The actual content to output
3. Attention Scores (Softmax Scaling)
– Scores are computed as:
\[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
\]
– d_k = dimension of keys (scaling prevents gradient instability).
4. Multi-Head Attention (MHA)
– GPT-4 uses multiple attention heads (e.g., 96 heads) in parallel.
– Each head learns different attention patterns (e.g., syntax vs. semantics).
– Outputs are concatenated and linearly projected.
3. Feedforward Neural Network (FFN)
After self-attention, the data passes through a position-wise FFN (applied independently to each token).
Structure:
\[
\text{FFN}(x) = \text{ReLU}(W_1 x + b_1) W_2 + b_2
\]
– Expands to a larger dimension (e.g., 4 × d_model) then compresses back.
– Introduces non-linearity (ReLU/GELU).
4. Layer Normalization & Residual Connections
– LayerNorm (Pre-LN in GPT-4)
– Normalizes activations before (not after) attention/FFN layers.
– Stabilizes training in deep networks.
– Residual (Skip) Connections
– Helps gradients flow deeper by adding the input back:
\[
\text{Output} = \text{LayerNorm}(x + \text{Attention}(x))
\]
5. GPT-4’s Special Optimizations
a) Sparse Attention (Mixture of Experts, MoE)
– Only a subset of neurons (“experts”) activate per input, reducing compute.
– Estimated 1T+ parameters, but only ~200B active per inference.
b) Rotary Position Embeddings (RoPE)
– Replaces traditional positional encodings for better long-context handling.
c) FlashAttention
– Optimizes GPU memory usage for faster attention computation.
6. How Text Generation Works (Autoregressive Decoding)
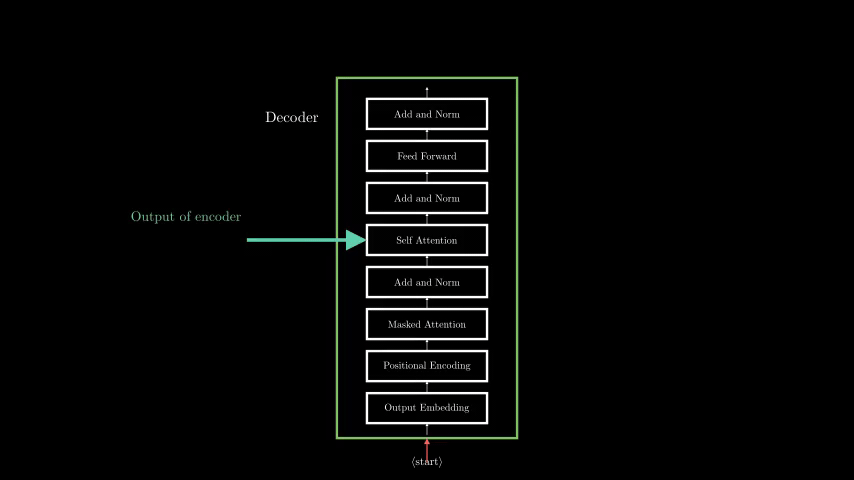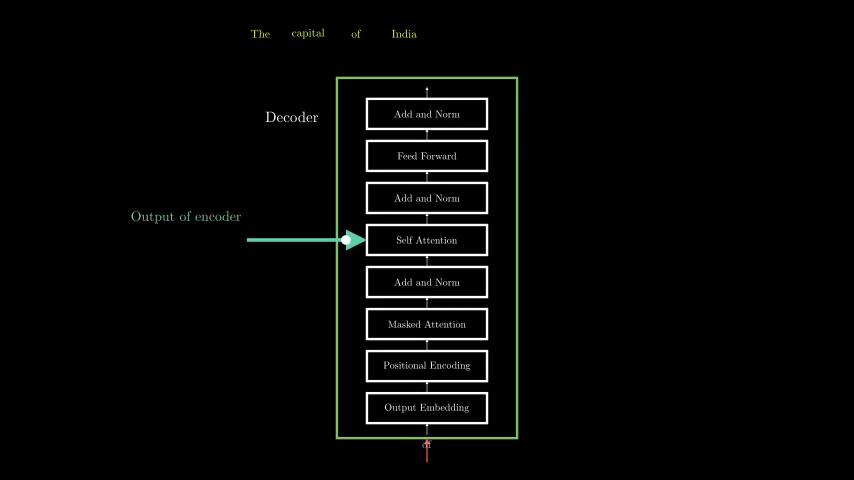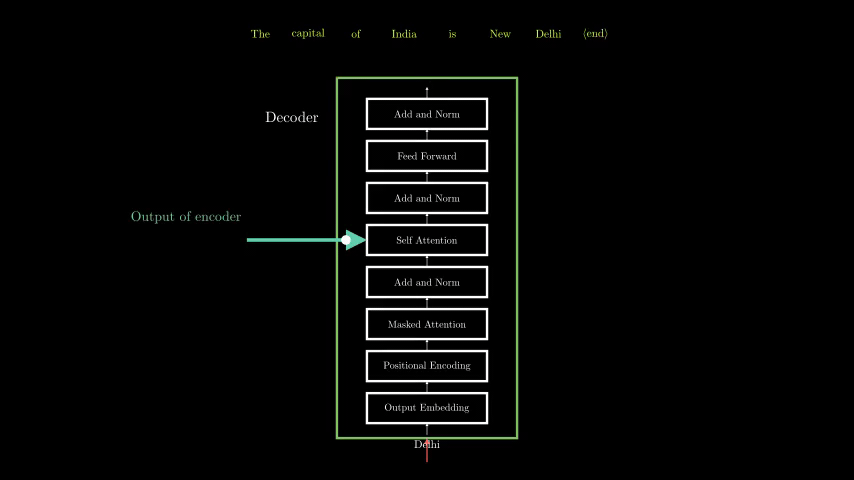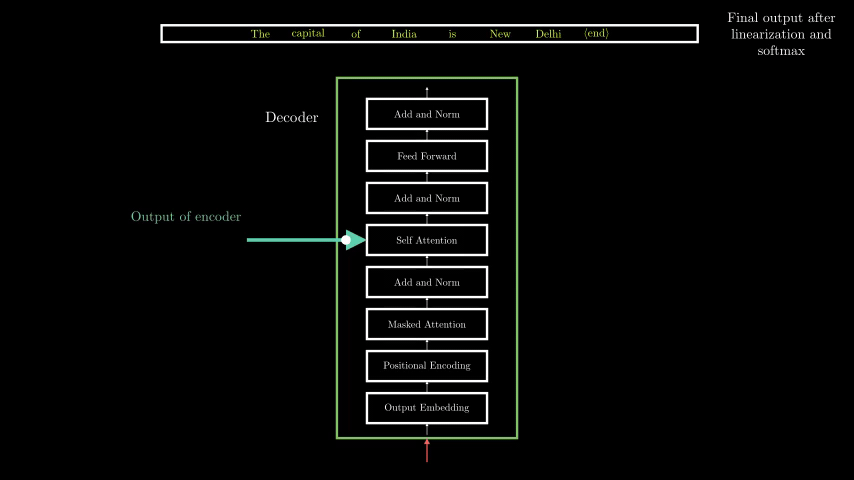
1. Input Prompt → Tokenized into subwords (e.g., "Hello" → [15496]).
2. Forward Pass → Computes logits for next token.
3. Sampling → Picks next token via:
– Greedy (argmax)
– Nucleus (top-p) sampling
4. Repeat until <EOS> (end-of-sequence) token appears.
7. Scaling Challenges & Solutions
| Problem | Solution |
|---|---|
| Memory Limits | Model parallelism (tensor/pipeline) |
| Slow Inference | KV caching + speculative decoding |
| High Training Cost | MoE + 3D parallelism (data/model/pipeline) |
Read: Shor’s Algorithm: Breaking RSA with Quantum Computing (Full Mathematical Breakdown)
If You Want to Implement a Mini Version?
1. Start with NanoGPT (1M params) → Understand attention.
2. Scale to Llama 3 (8B+ params) → Experiment with LoRA fine-tuning.
3. Deploy optimized inference with vLLM or TensorRT-LLM.


