and How Data Passes Through Them")



, and Neural Networks in a structured way")
")
 That You’ll Want to Buy for yourself")





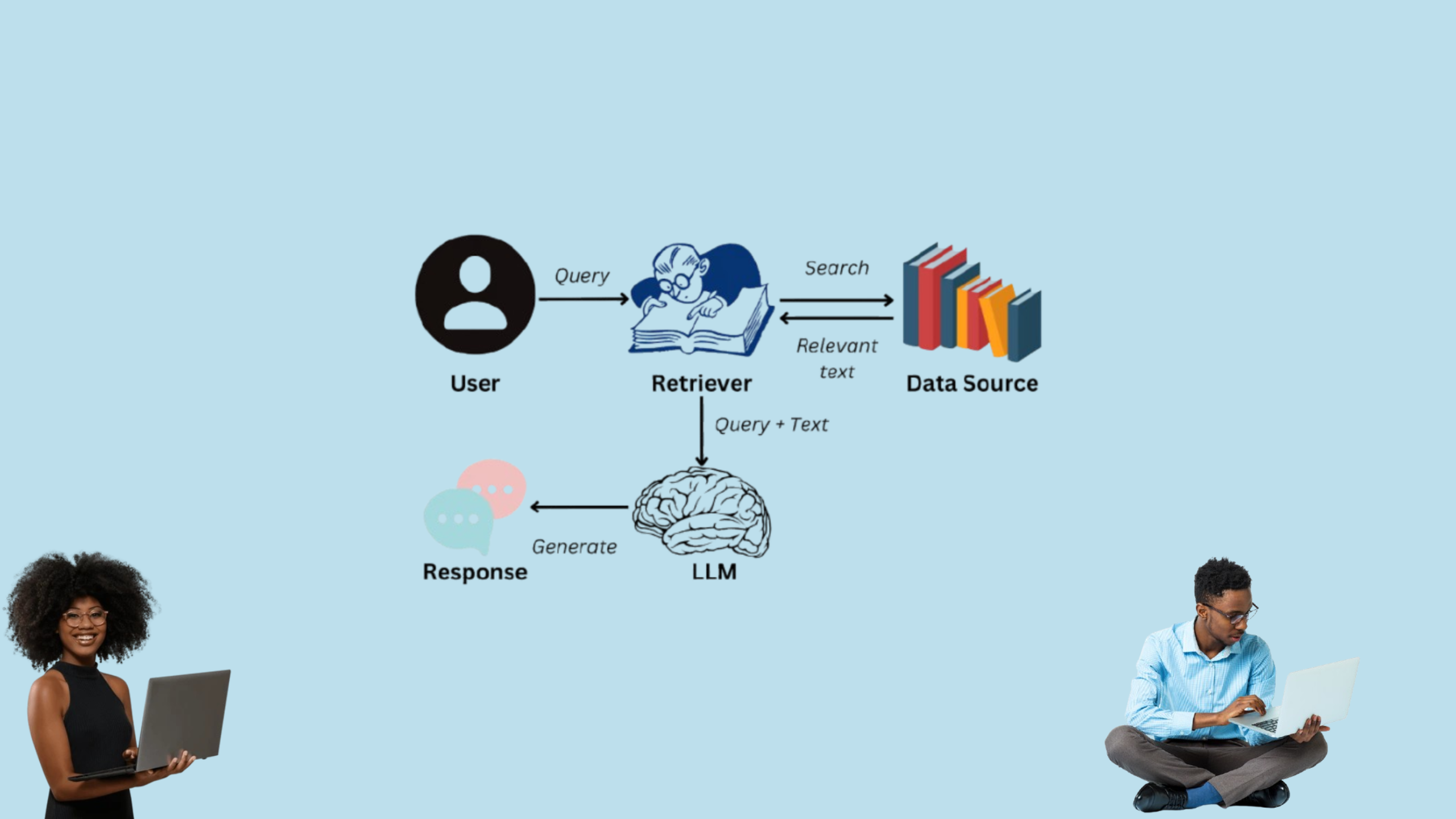
Retrieval-Augmented Generation (RAG) is quickly redefining how we build and deploy intelligent AI systems. It isn’t a replacement for large language models (LLMs)—it’s the missing piece that makes them useful in real-world settings.
With hallucinations, outdated knowledge, and limited memory being persistent LLM issues, RAG introduces a smarter approach: retrieve factual information from reliable sources, augment the user’s prompt, and generate a response grounded in reality. If you’re building chatbots, assistants, or knowledge tools, RAG is a must-have pattern in your stack.
Intro to ML
In this post, we’ll break down what a RAG framework is, why it matters, the best open-source tools you can use right now, and how to avoid the most common pitfalls.
What Is a RAG Framework?
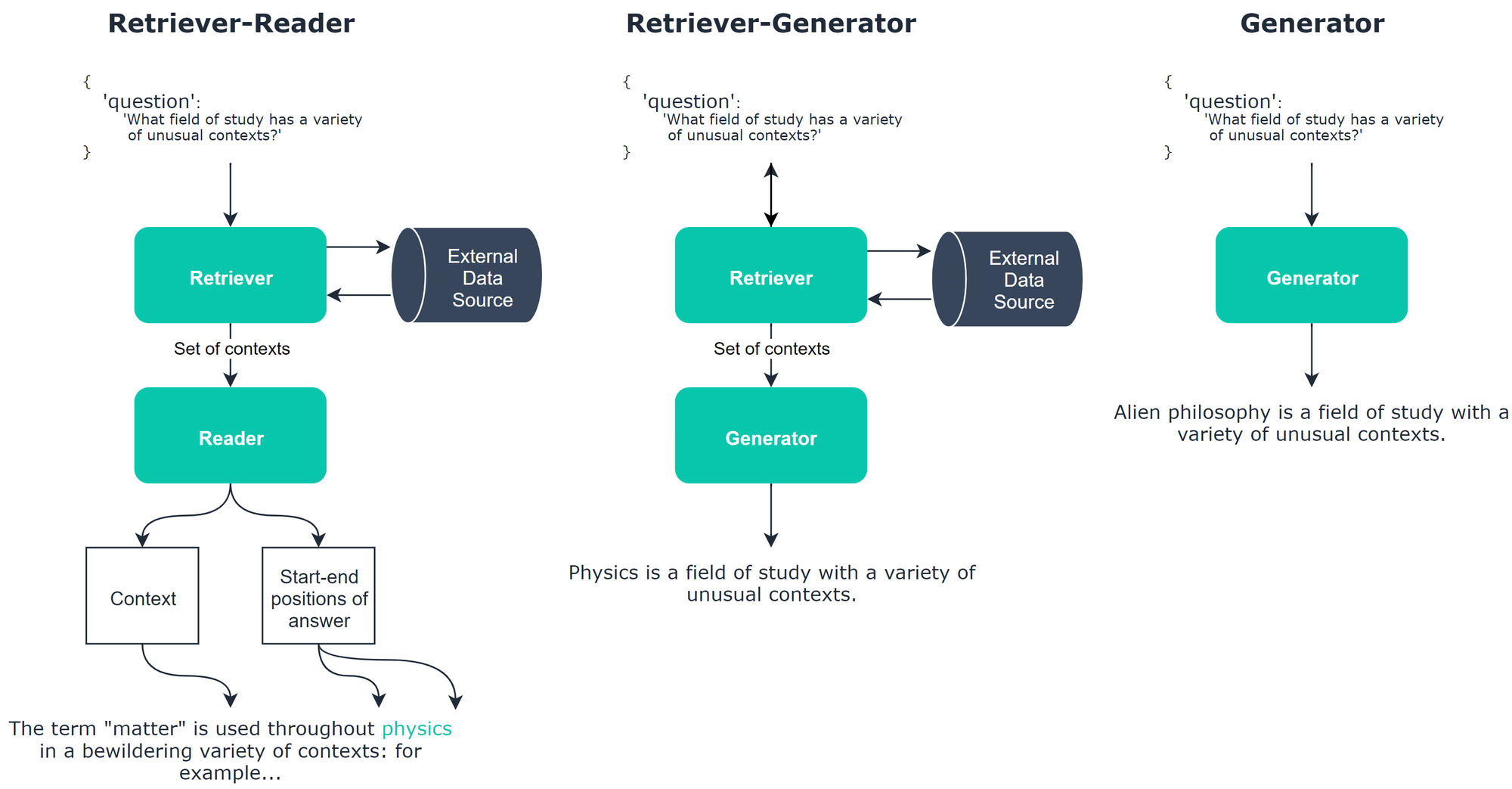
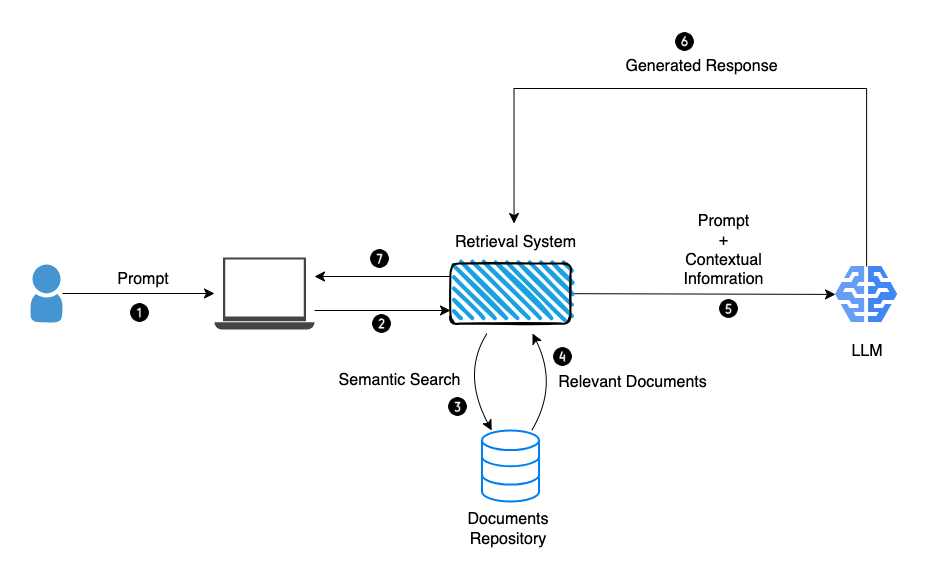
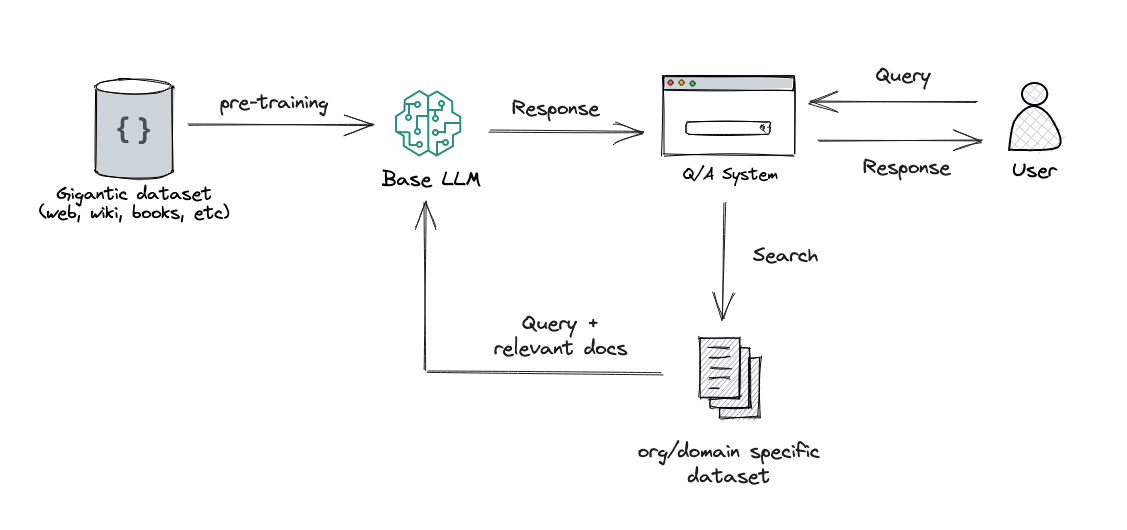
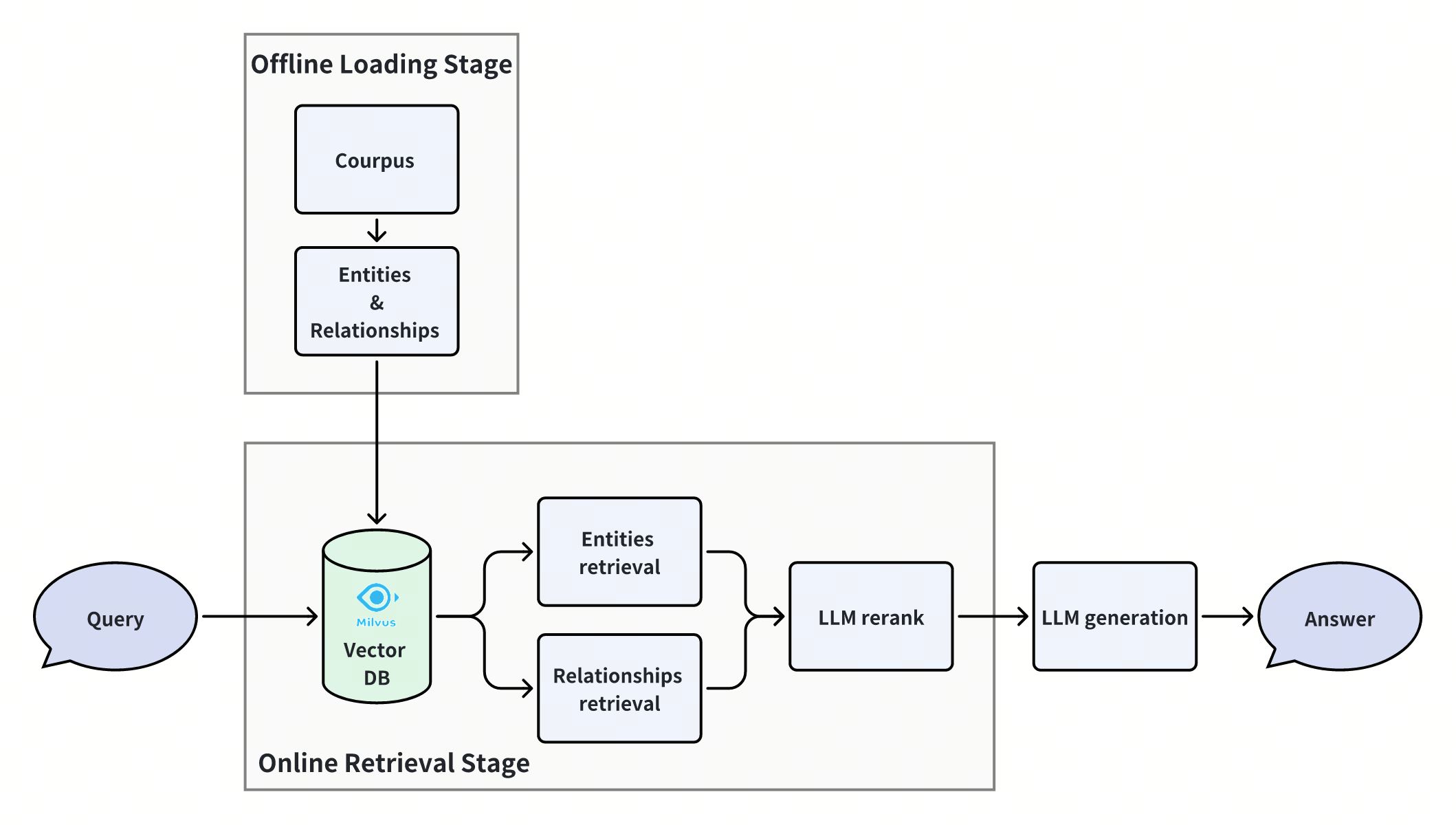
RAG stands for Retrieve, Augment, Generate. Instead of relying solely on the model’s internal knowledge, a RAG framework pulls in relevant external data in real time to guide generation.
Here’s how it works:
- Retrieve: Search a knowledge base using a vector store or keyword index.
- Augment: Inject the retrieved content into the prompt.
- Generate: Let the LLM answer based on both the original query and augmented context.
This approach overcomes many LLM limitations:
- Removes hallucinations
- Handles long-term memory
- Works with evolving knowledge
- Enables explainability via sources
✅ Why Use a RAG Framework?
LLMs alone are generalists. RAG transforms them into domain experts by plugging in your own data—product docs, tickets, wikis, and more—without needing to fine-tune.
Benefits include:
- Factuality: Grounded answers from your own verified content.
- Domain focus: Answer questions only you can answer.
- Low maintenance: Swap in fresh content, no retraining required.
- Scalability: Ideal for QA systems, internal chatbots, research tools, and more.
The Best Open-Source RAG Frameworks (2025 Edition)
Below are the leading frameworks helping teams build retrieval-augmented systems at scale. Each is unique in philosophy, tooling, and ease of use.
1. Haystack
- Stars: ~13.5k
- Deployment: Docker, K8s, Hugging Face
- Strengths: Modular components, multi-backend support, rich doc tools
- Use Cases: Enterprise-grade QA, document chat, legal search
2. LlamaIndex

- Stars: ~13k
- Deployment: Python, notebooks
- Strengths: Easy data connectors, FAISS support, streaming queries
- Use Cases: Personalized knowledge bots, academic tools
3. LangChain
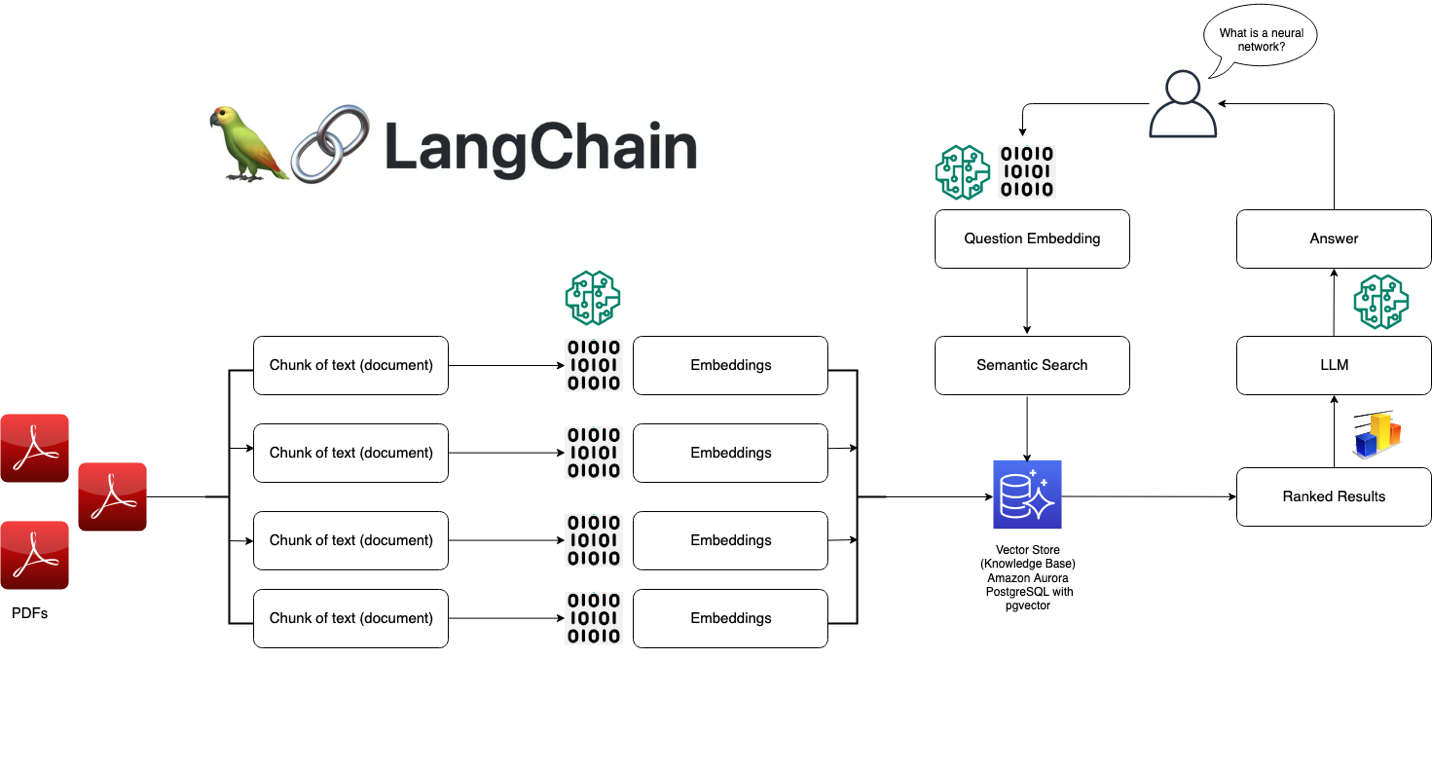
- Stars: ~72k
- Deployment: Python/JS, cloud ready
- Strengths: Agents, chains, tools, memory
- Use Cases: LLM apps, agents, dynamic query flows
4. RAGFlow
- Stars: ~1.1k
- Deployment: Docker + FastAPI
- Strengths: Visual chunking, clean configs, Weaviate integration
- Use Cases: Law, financial QA, prototyping
5. txtAI
- Stars: ~3.9k
- Deployment: Python CLI
- Strengths: Lightweight, scoring, PDF/search integration
- Use Cases: Semantic search, local dev bots
6. Cognita
![Cognita : A Truly Unified RAG Framework : Part 1 [D] : r/MachineLearning](https://preview.redd.it/cognita-a-truly-unified-rag-framework-part-1-d-v0-myakqmkq7duc1.png?width=1318&format=png&auto=webp&s=2f64fa7010921f255fe71cebb71fffe8de652551)
- Deployment: Docker + UI
- Strengths: Developer-friendly UI, backend flexibility
- Use Cases: Business-facing assistants, UI demos
7. LLMWare
- Stars: ~2.5k
- Deployment: CLI, REST
- Strengths: Document parsing, local deployment, OpenAI optional
- Use Cases: Private RAG systems for regulated industries
8. STORM

- Deployment: Source install
- Strengths: Graph reasoning, outline-to-article pipelines
- Use Cases: Research QA, multi-source synthesis
9. R2R (Reason to Retrieve)
- Deployment: REST API
- Strengths: Multimodal inputs, hybrid search, knowledge graphs
- Use Cases: AI research, academic assistants
10. EmbedChain
- Stars: ~3.5k
- Deployment: Python lib, SaaS
- Strengths: Simple file ingest, RAG in minutes
- Use Cases: Startups, internal tooling, fast prototyping
And More…
Other promising frameworks include:
- RAGatouille: ColBERT-based retriever testing
- Verba: Weaviate-powered memory bots
- Jina AI: Multimodal pipelines for enterprise
- Neurite: Experimental neural-symbolic stack
- LLM-App: Hackathon-ready RAG starter kits
⚖️ Comparison Table
| Framework | Deployment | Customizability | Advanced Retrieval | Best For |
|---|---|---|---|---|
| Haystack | Docker, K8s | High | Yes | Enterprise search/QA |
| LlamaIndex | Python local | High | Yes | Document-aware agents |
| LangChain | Python/JS/cloud | High | Yes | Agent-driven LLM apps |
| RAGFlow | Docker | Medium | Yes | Legal/structured QA |
| txtAI | Python | Medium | Basic | Lightweight search/chat |
| Cognita | Docker + UI | High | Yes | Internal business UIs |
| LLMWare | CLI, API | High | Yes | On-prem secure deployments |
| R2R | REST API | High | Yes | Multimodal knowledge systems |
| EmbedChain | Python/SaaS | Medium | Basic | Simple domain bots |
⚠️ Common Pitfalls in RAG
1. Indexing Too Much Junk
If you feed garbage into your vector store, you’ll get garbage back. Index only well-structured, relevant, and clean data. Preprocess aggressively.
2. Ignoring Token Limits
If your retrieved context + query exceeds the LLM’s limit (e.g., 4K tokens), chunks will get cut off. Prioritize and summarize before inject.
3. Optimizing for Recall, Not Precision
Don’t try to return too many documents. Focus on precise matches, not just many. Too much context hurts more than it helps.
4. No Logs, No Debugging
Track user queries, retrieved results, final prompt, and model responses. This is vital for improving relevance and trustworthiness.
✅ Conclusion
RAG isn’t just a clever pattern—it’s a reliable bridge between static model training and dynamic, real-world use. Done right, it lets you ship helpful, honest AI systems that feel smart and stay grounded.
Start with the right framework for your stack. Clean your data. Monitor your flow. Then watch as your LLMs become trusted advisors instead of hallucinating interns.