





 and How Data Passes Through Them")



, and Neural Networks in a structured way")
")

")




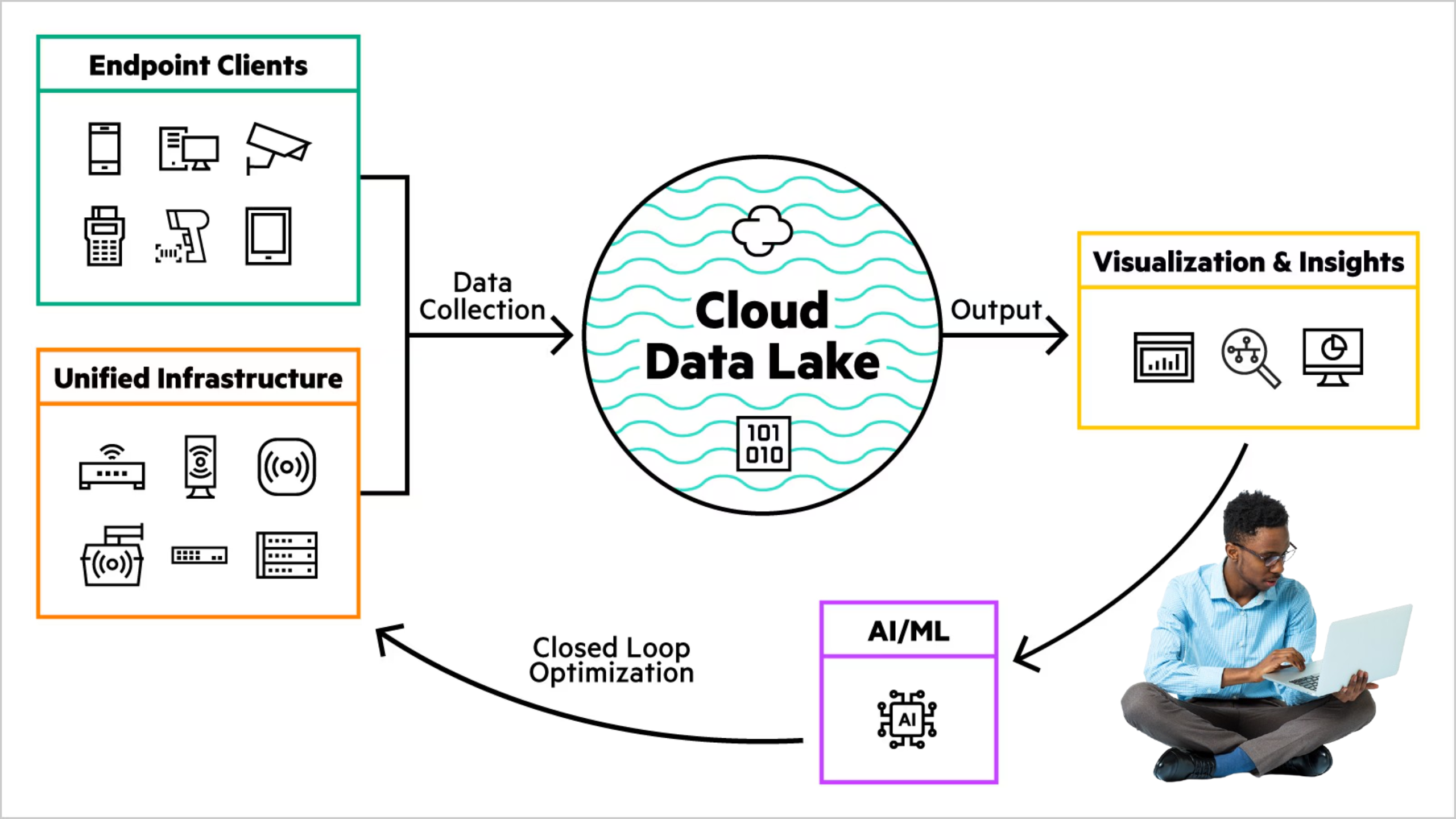
What is a Data Lake?
A data lake is a centralized repository that stores vast amounts of raw data in its native format. Unlike traditional data warehouses, which require predefined schemas and are optimized for structured data, data lakes store unprocessed data. This approach provides greater flexibility for advanced analytics, real-time data processing, and machine learning.
Key Benefits:
Scalability – Store petabytes of data, including structured, semi-structured, and unstructured formats.
Cost-Effectiveness – Pay-as-you-go models offered by cloud providers make them ideal for growing businesses.
Flexibility – Retain data in its raw format, enabling diverse analytics and machine learning use cases.
Data Lake Architecture: Core Foundations
A data lake architecture typically consists of the following layers:
1. Data Ingestion
Handles transferring data into the lake from various sources, such as IoT devices, social media, and transactional systems.
Common tools:
Batch Ingestion – AWS Glue, Apache Sqoop
Real-Time Streaming – Apache Kafka, Apache NiFi
2. Data Storage
Scalable platforms like Amazon S3, Azure Data Lake Storage, or Hadoop HDFS store raw, unprocessed data.
3. Data Processing
Frameworks like Apache Spark and Databricks clean and transform the data, preparing it for consumption.
4. Data Consumption
BI tools (Power BI, Tableau) and SQL engines enable insights, while APIs provide programmatic access.
5. Data Security and Governance
Access controls, encryption, and monitoring ensure compliance with regulations like GDPR and HIPAA.
How to Build a Data Lake: Step-by-Step Guide
Step 1: Define Use Cases and Objectives
Identify business goals (e.g., real-time analytics, machine learning).
Define data types: structured, semi-structured, or unstructured.
Example: An e-commerce company might use a data lake to analyze customer behavior and optimize inventory.
Step 2: Choose the Right Platform
Select a platform based on business needs:
Cloud-Based – Amazon S3 (AWS), Azure Data Lake Storage, Google Cloud Storage
On-Premises – Hadoop HDFS for tighter control
Tip: Choose a platform compatible with your existing tech stack.
Step 3: Design the Architecture
Raw Layer – Stores unprocessed data
Curated Layer – Holds cleaned and standardized data
Processed Layer – Contains aggregated data ready for analytics
Use metadata catalogs like Apache Atlas or AWS Glue Data Catalog to track data lineage.
Step 4: Set Up Data Ingestion Pipelines
Use Apache Kafka for real-time ingestion
Use AWS Glue or Azure Data Factory for batch ingestion
Example: Capture live website interactions with Kafka and batch-process historical sales data via Glue.
Step 5: Implement Data Processing Frameworks
Use Apache Spark for distributed processing
Standardize data with ETL workflows (e.g., deduplication, normalization)
Step 6: Ensure Security and Compliance
Implement Role-Based Access Control (RBAC)
Encrypt data at rest and in transit
Example: Mask patient identifiers for healthcare data compliance.
Step 7: Enable Data Access and Analytics
Query engines like Amazon Athena enable SQL-based data exploration
Visualization tools like Tableau or Power BI create intuitive dashboards
Tips from Industry Experts
Roja Boina, Senior Advisor at Evernorth
Focus on scalable cloud storage and unified metadata catalogs
Use open file formats like Parquet for flexibility
Raphaël Mansuy, Co-Founder of Quantalogic
Understand data sources and business goals before building
Pair cloud storage (AWS S3) with compute engines (Apache Spark) for efficiency
Building a Data Lake on Specific Platforms
How to Build a Data Lake on AWS
Use Amazon S3 buckets for raw, processed, and curated data
Set up ingestion pipelines with AWS Glue or AWS DataSync
Query data with Amazon Athena or integrate with AWS Lake Formation for governance
How to Build a Data Lake on Azure
Use Azure Data Lake Storage Gen2 for hierarchical storage
Automate ingestion via Azure Data Factory
Enable analytics with Azure Synapse Analytics and governance with Azure Purview
How to Build a Data Lake on Hadoop
Store data in Hadoop HDFS
Use Apache Hive for metadata management
Process data with Apache Spark
Learn to Build a Data Lake from Scratch with ProjectPro
ProjectPro offers real-world, project-based learning to help you master data engineering. Gain hands-on experience with tools like Apache Spark, Databricks, and AWS services by working on practical use cases.
Check out the project “Building an Analytical Platform for eCommerce” to simulate real-world data lake and lakehouse setups.
FAQs on Building a Data Lake
1. What is the architecture of a data lake?
It includes layers for data ingestion, storage, and analytics, supporting diverse data types.
2. What are the three layers of a data lake?
Ingestion Layer – Collects raw data
Storage Layer – Centralized repository for unprocessed data
Analytics Layer – Processes and analyzes data
3. What is a data lake in ETL?
A data lake serves as a storage system for raw data before ETL processing, offering flexibility for diverse analytics.
Ready to build your data lake? Follow this guide to unlock the full potential of your data and drive innovation in your organization.



