





 and How Data Passes Through Them")



, and Neural Networks in a structured way")
")




")

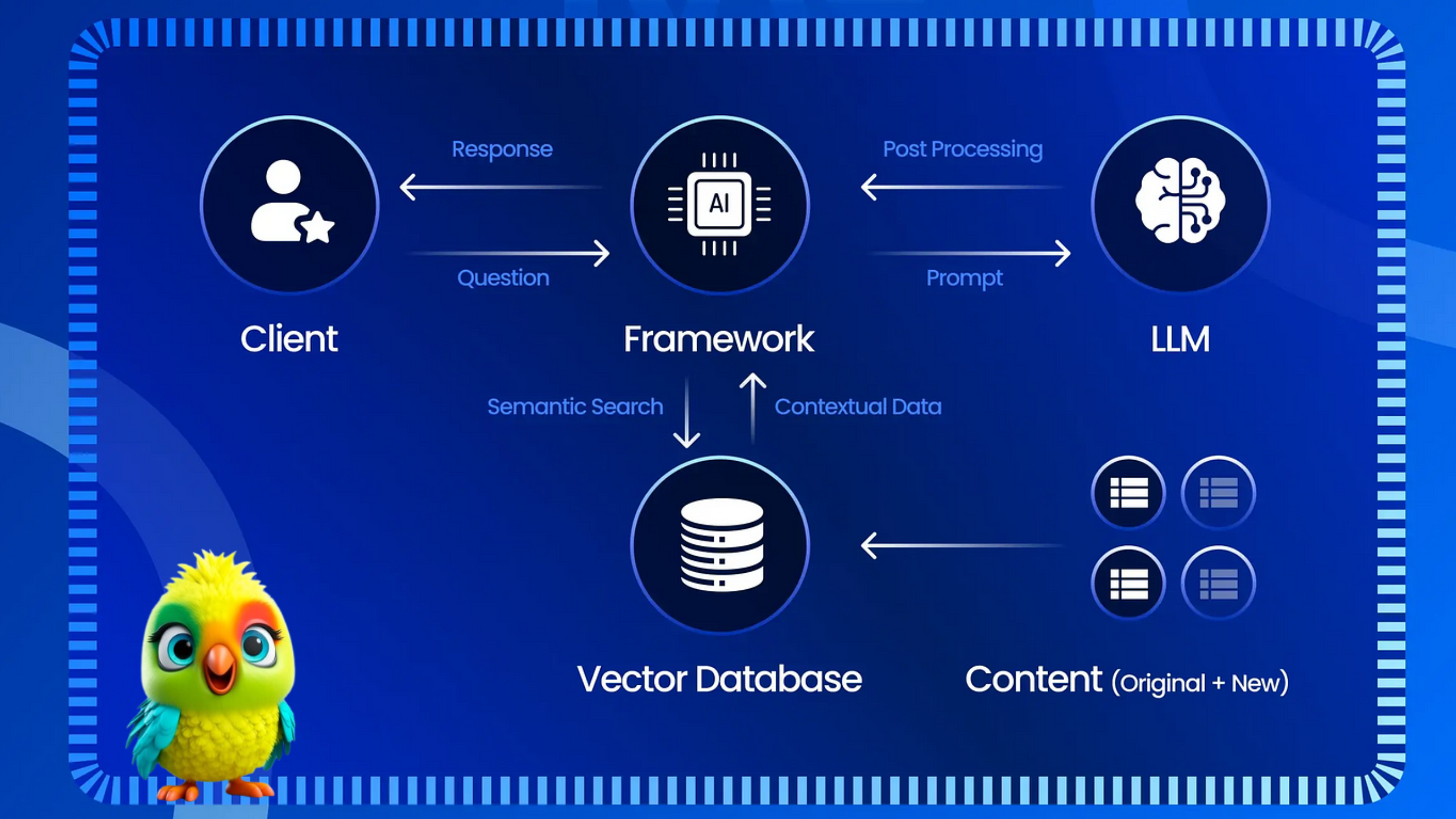
Retrieval-Augmented Generation (RAG) enhances LLM text generation by incorporating external knowledge sources, making responses more accurate, relevant, and up-to-date. RAG combines an information retrieval component with a text generation model, allowing the LLM to access and process information from external databases before generating text. This approach addresses challenges like domain knowledge gaps, factuality issues, and hallucinations often associated with LLMs.
Key Aspects of RAG:
- Augmentation:
RAG augments LLMs with external knowledge, bridging the gap between the LLM’s inherent knowledge and the vast, dynamic repositories of external databases.
- Retrieval:
RAG uses retrieval mechanisms to find relevant information from external databases based on user queries.
- Generation:
The LLM uses the retrieved information as context to generate more accurate and contextually appropriate responses.
Benefits of RAG:
- Reduced Hallucination:
By grounding the LLM in external knowledge, RAG reduces the likelihood of the LLM generating incorrect or nonsensical information (hallucinations).
- Improved Accuracy:
RAG ensures that LLMs generate responses that are factually accurate and aligned with the latest information.
- Continuous Knowledge Updates:
RAG allows for easy integration of new or updated information without retraining the underlying LLM.
- Domain-Specific Knowledge:
RAG enables LLMs to be specialized for specific domains or organizations, providing them with domain-specific knowledge.
How RAG Works:
- User Query:
A user submits a query to the LLM.
- Retrieval:
The LLM sends the query to a retrieval model (often an embedding model) that converts it into a numerical representation.
- Knowledge Base Search:
The numerical representation is used to search a vector database containing embeddings of external knowledge sources.
- Information Retrieval:
The retrieval model identifies the most relevant information from the knowledge base.
- Text Generation:
The LLM uses the retrieved information as context to generate a response to the user’s query.
Examples of RAG Applications:
- FAQ Bots:RAG can be used to create FAQ bots that can answer questions using an organization’s internal knowledge base.
- Research Assistants:RAG can be used to build research assistants that can access and synthesize information from various sources.
- Customer Support Tools:RAG can be used to create customer support tools that can provide accurate and relevant answers to customer queries.
Welcome to this beginner-friendly guide! In this project, you’ll learn how to:
- Use LLaMA, a powerful large language model (LLM), for text generation.
- Retrieve relevant text snippets using Sentence Transformers, a popular tool for embedding text.
- Combine these techniques to answer questions based on context provided from retrieved snippets.
Run this command to install everything you need:
1 2 3 | !pip install -Uq sentence-transformers |
️ Setup: Installing the Necessary Libraries
First, we need to install some Python libraries that will help us:
transformers: Provides access to LLaMA and other pre-trained models for text generation.sentence-transformers: Helps generate embeddings, which are essential for comparing text snippets.
1 2 3 4 5 | from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline from sentence_transformers import SentenceTransformer import torch |
Step 1: Model Setup and Tokenizer
1 2 3 4 5 6 7 | chechpoint = "meta-llama/Llama-3.2-3B-Instruct" tokenizer = AutoTokenizer.from_pretrained(chechpoint) llama_model = AutoModelForCausalLM.from_pretrained(chechpoint, torch_dtype=torch.bfloat16) generator = pipeline("text-generation", model=llama_model, tokenizer=tokenizer, device="cuda") # Create a simple text generation pipeline |
What’s happening:
We specify the LLaMA 3.2B Instruct model from Meta
The tokenizer converts text to tokens (numerical representations) the model can understand
We load the model weights with bfloat16 precision (memory-efficient floating point format)
Create a text generation pipeline that handles:
Tokenization
Model inference
Decoding back to text
Runs on GPU (“cuda”) for faster processing
Step 2: Text Snippet Retrieval Setup
1 2 3 4 5 6 7 8 9 | text_snippets = [ "Fiona thanked Ethan for his unwavering support and promised to cherish their friendship.", "As they ventured deeper into the forest, they encountered a wide array of obstacles.", "Ethan and Fiona crossed treacherous ravines using rickety bridges, relying on each other's strength.", "Overwhelmed with joy, Fiona thanked Ethan and disappeared into the embrace of her family.", "Ethan returned to his cottage, heart full of memories and a smile brighter than ever before.", ] |
Purpose:
We create a small knowledge base of text snippets that will serve as our retrieval corpus
In a real application, this would typically be a much larger database or document collection
Step 3: Convert text snippets to embeddings for later comparison.
1 2 3 4 | model = SentenceTransformer("all-MiniLM-L6-v2") embeddings_text_snippets = model.encode(text_snippets) # Generate embeddings for the text snippets |
Key concepts:
We use the “all-MiniLM-L6-v2” model which is optimized for semantic similarity tasks
encode()converts each text snippet into a 384-dimensional vector (embedding)These embeddings capture semantic meaning in a way that allows mathematical comparison
Step 4: Create a function to retrieve the closest matching snippet using cosine similarity.
1 2 3 4 5 6 7 | def retrieve_snippet(query): query_embedded = model.encode([query]) # Encode the query to obtain its embedding similarities = model.similarity(embeddings_text_snippets, query_embedded) # Calculate cosine similarities between the query embedding and the snippet embeddings retrieved_texts = text_snippets[similarities.argmax().item()] # Retrieve the text snippet with the highest similarity return retrieved_texts |
How retrieval works:
The user’s query is converted to an embedding
We compute cosine similarity between query embedding and all snippet embeddings
Cosine similarity measures angle between vectors (1 = identical, -1 = opposite)
The snippet with highest similarity score is returned
Step 5: Create a function to generate the answer based on the retrieved snippet and query.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # In this step, we utilize the retrieved context snippets to generate a relevant answer using LLaMA, exemplifying the power of RAG in enhancing the quality of responses. def ask_query(query): retrieved_texts = retrieve_snippet(query) # Prepare the messages for the text generation pipeline messages = [ {"role": "system", "content": "You are a helpful AI assistant." "Provide one Answer ONLY the following query based on the context provided below. " "Do not generate or answer any other questions. " "Do not make up or infer any information that is not directly stated in the context. " "Provide a concise answer." f"{retrieved_texts}"}, {"role": "user", "content": query} ] # Generate a response using the text generation pipeline response = generator(messages, max_new_tokens=128)[-1]["generated_text"][-1]["content"] print(f"Query: \n\t{query}") print(f"Context: \n\t{retrieved_texts}") print(f"Answer: \n\t{response}") |
RAG Process:
Retrieve the most relevant context for the query
Construct a prompt that:
Sets system instructions
Includes retrieved context
Presents the user query
Key instructions to the model:
Answer only based on provided context
Be concise
Don’t hallucinate information
Generate response limited to 128 new tokens
Step 6: Ask a Question
1 2 3 4 5 6 7 8 9 10 11 12 13 | query = "Why did Fiona thank Ethan?" ask_query(query) OUTPUT: Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation. Query: Why did Fiona thank Ethan? Context: Fiona thanked Ethan for his unwavering support and promised to cherish their friendship. Answer: Fiona thanked Ethan for his unwavering support. |
Why this works:
The retrieval system found the most relevant snippet about Fiona thanking Ethan
The LLM was constrained to only use this context
The response is accurate and directly supported by the context
Key Benefits of This RAG Approach
Factual Accuracy: By grounding responses in retrieved documents, we reduce hallucinations
Up-to-date Information: Can update the knowledge base without retraining the model
Transparency: Users can see the source context for answers
Efficiency: Don’t need to fine-tune the large language model
This implementation shows a basic RAG pipeline that can be extended with:
Larger document collections
More sophisticated retrieval methods
Better prompt engineering
Post-processing of responses


