and How Data Passes Through Them")



, and Neural Networks in a structured way")
")
 That You’ll Want to Buy for yourself")






Introduction
As the AI landscape rapidly evolves, vision architectures are undergoing a revolution. We’ve moved beyond CNNs into the age of Vision Transformers (ViTs), hybrid systems like SigLIP, long-sequence models such as Mamba, and powerful multimodal models like Qwen-VL. Then there’s STORM—a new architecture combining selective attention, token reduction, and memory.
This blog walks you through:
-
Vision Transformers (ViTs) – Core architecture
-
Mamba Layers – State space models for long-sequence efficiency
-
STORM – A hybrid transformer architecture
-
SigLIP – Efficient CLIP replacement
-
Qwen-VL – Open-source multimodal giant
-
Full architectural breakdowns and how to build them
Let’s begin.
1. Vision Transformers (ViTs): The Foundation
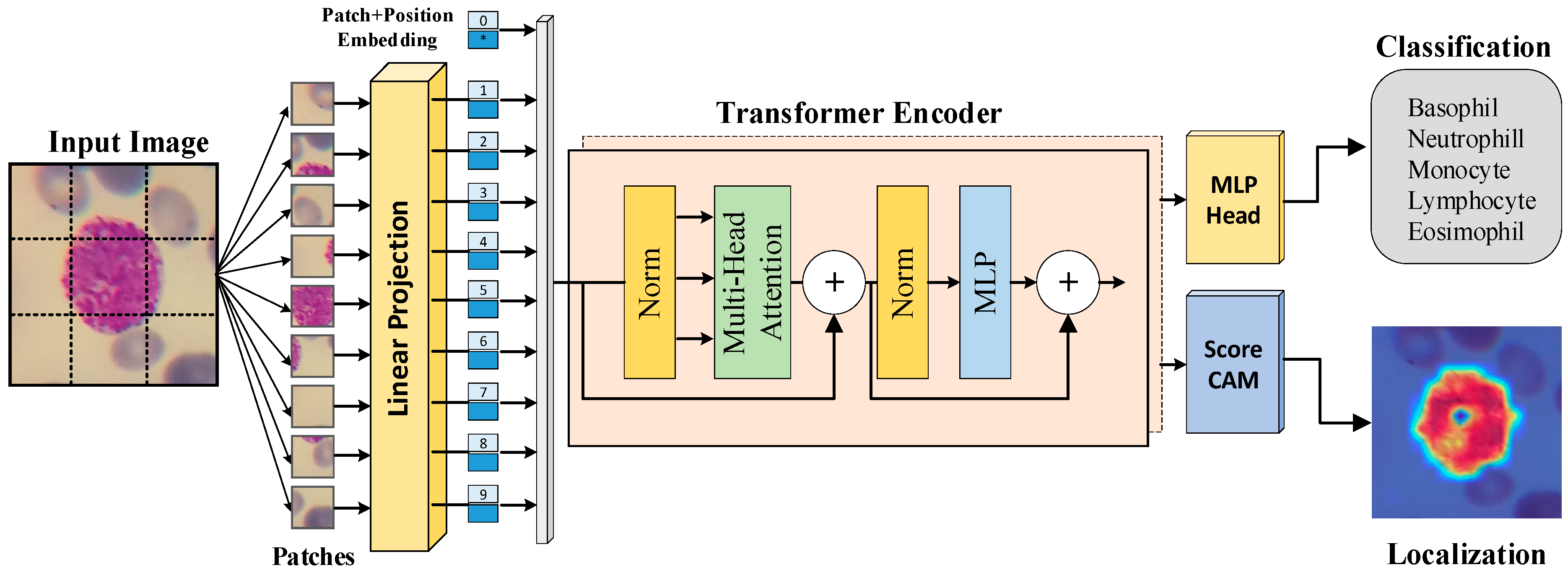
Architecture
-
Patch Embedding: Split an image (e.g., 224×224) into fixed-size patches (e.g., 16×16).
-
Linear Projection: Each patch is flattened and linearly projected into a vector.
-
Positional Embedding: Add positional info to preserve spatial structure.
-
Transformer Encoder Blocks:
-
Multi-head self-attention
-
LayerNorm
-
MLP with GELU activation
-
Skip connections
-
-
Classification Head: [CLS] token is passed to an MLP head for classification.
Key Equations
2. Mamba Layers: Sequence Modeling Revolution
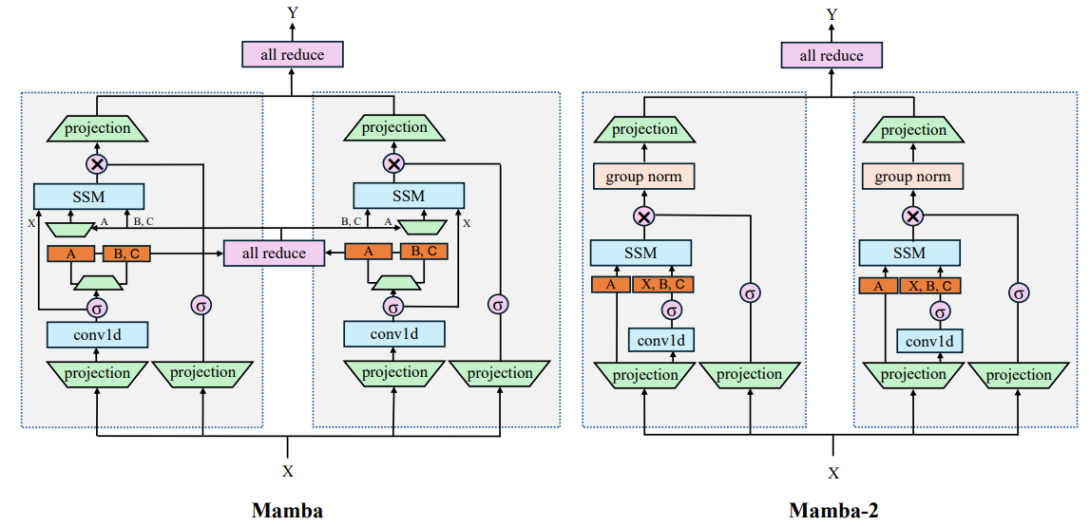
Mamba (by Princeton & Together AI) introduces a selective state space model for high-throughput long sequence modeling.
Why It Matters
-
Efficient for long sequences
-
Linear time complexity with sequence length
-
Ideal for time-series, audio, video, and vision
Architecture
Each Mamba layer processes inputs using:
-
A learned input projection
-
A selective scan mechanism (like convolution + memory)
-
Gating for dynamic selection
-
Normalization + residuals
⛓️ How It Works
Use in Vision:
Can replace attention blocks in ViT or be hybridized (like in STORM).
3. ⚡ STORM: Speed Meets Scale

STORM (Selective Token Retention and Mamba) introduces a clever hybrid model using:
-
Selective attention: Keeps only important tokens (like TokenLearner).
-
Mamba layers: For long-range sequence efficiency.
-
Cross-layer memory: Preserves contextual info between layers.
️ Architecture Step-by-Step
-
Patchify input image
-
Project patches + add positional embeddings
-
Alternate blocks:
-
Token Retention module: reduce token count dynamically
-
Mamba Layer: scan across reduced tokens
-
-
Global memory pool updated across layers
-
Final aggregation + classification head
✅ Benefits
-
Fewer tokens → faster inference
-
Handles longer input contexts (e.g., video frames, high-res images)
-
Preserves accuracy by keeping informative tokens
4. SigLIP: Efficient CLIP-style Vision-Language Learning
SigLIP (by Google Research) modifies CLIP’s contrastive loss:
-
Uses Sigmoid cross-entropy instead of softmax + temperature.
-
Improves stability and training efficiency.
How SigLIP Works
-
Encode image and text independently using ViT and Transformer.
-
Normalize embeddings
-
Compute pairwise similarity matrix
-
Apply sigmoid loss (binary cross-entropy with labels as 1 if match, else 0).
SigLIP Loss
✅ Advantages
-
No need for negative mining
-
More robust to noise
-
Compatible with massive datasets (LAION, CC3M)
5. Qwen-VL: Open Source Multimodal Powerhouse
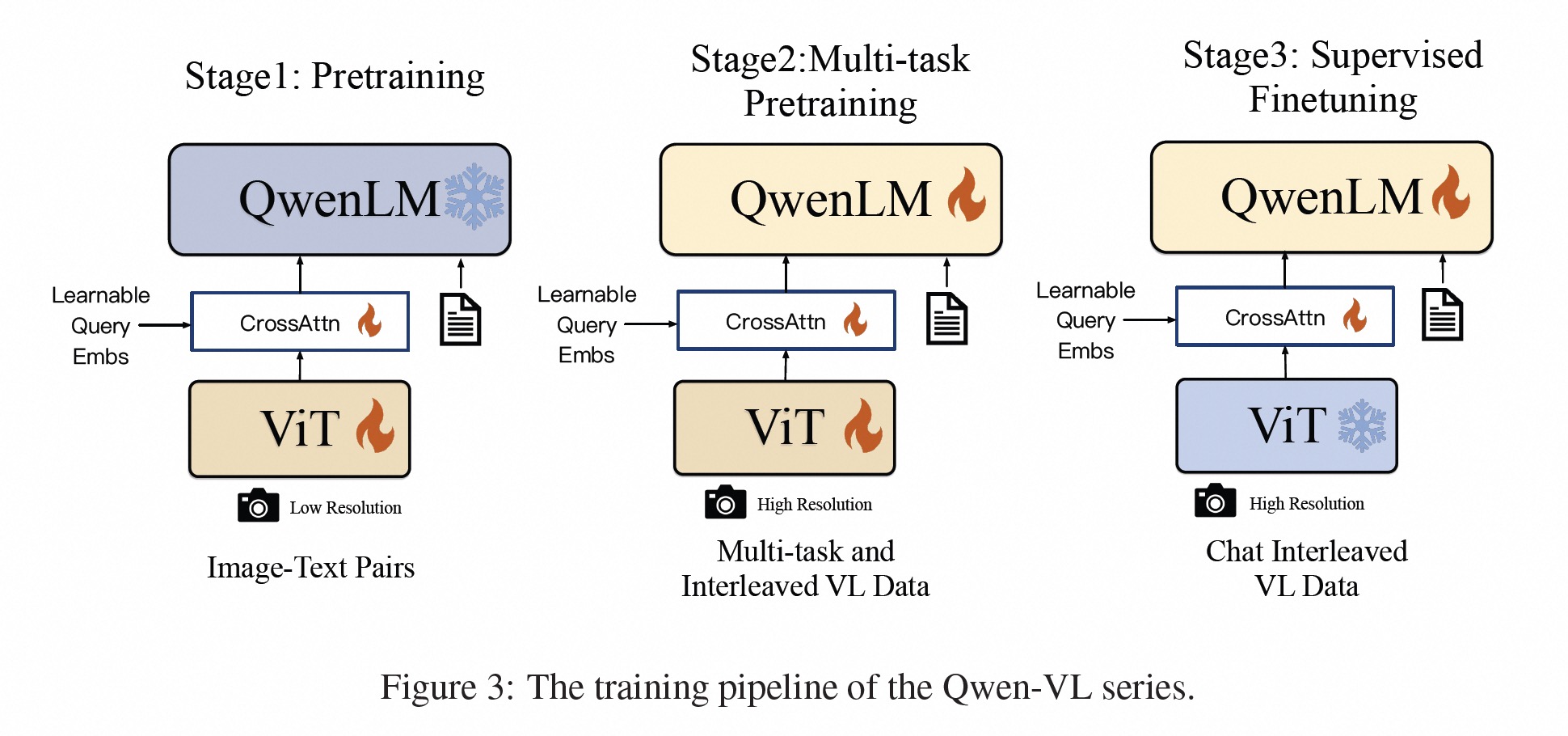
Qwen-VL is Alibaba’s open multimodal LLM, extending Qwen-7B with:
-
Vision encoder: Typically a CLIP ViT-G/14 or Swin
-
Multimodal Adapter: Projects vision embeddings into LLM token space
-
Qwen LLM Decoder: Generates answers with cross-attention on vision tokens
️ Qwen Architecture
Supports vision-language instruction tuning and few-shot multimodal prompting.
How to Build These Architectures
Let’s outline steps for each:
✅ Vision Transformer
✅ Mamba Layer
✅ STORM
-
Use a TokenLearner module to dynamically drop less important tokens
-
Insert Mamba or attention blocks
-
Maintain memory vector updated each layer
✅ SigLIP
-
Use CLIP-style architecture
-
Modify the loss to:
✅ Qwen-VL
Use HuggingFace or Alibaba’s repo:
Final Thoughts
These architectures—ViTs, Mamba, STORM, SigLIP, Qwen—are shaping the future of efficient, scalable vision and multimodal understanding. Whether you’re building research-grade models or production ML systems, understanding their internals will let you innovate and optimize.
Bonus: Combine Them!
Imagine building a pipeline where:
-
STORM encodes long-form video
-
Mamba compresses tokens for efficient modeling
-
SigLIP aligns vision and language
-
Qwen decodes responses from rich vision-text input
This is not science fiction. This is today.