





 and How Data Passes Through Them")



, and Neural Networks in a structured way")
")





 – 2025 Edition")

Introduction
As large language models (LLMs) become increasingly multimodal—capable of reasoning across text, images, audio, and video—a key bottleneck remains: token inefficiency. Particularly in the realm of long video understanding, traditional tokenization methods lead to rapid input length explosion, making processing long videos infeasible without aggressive downsampling or truncation.
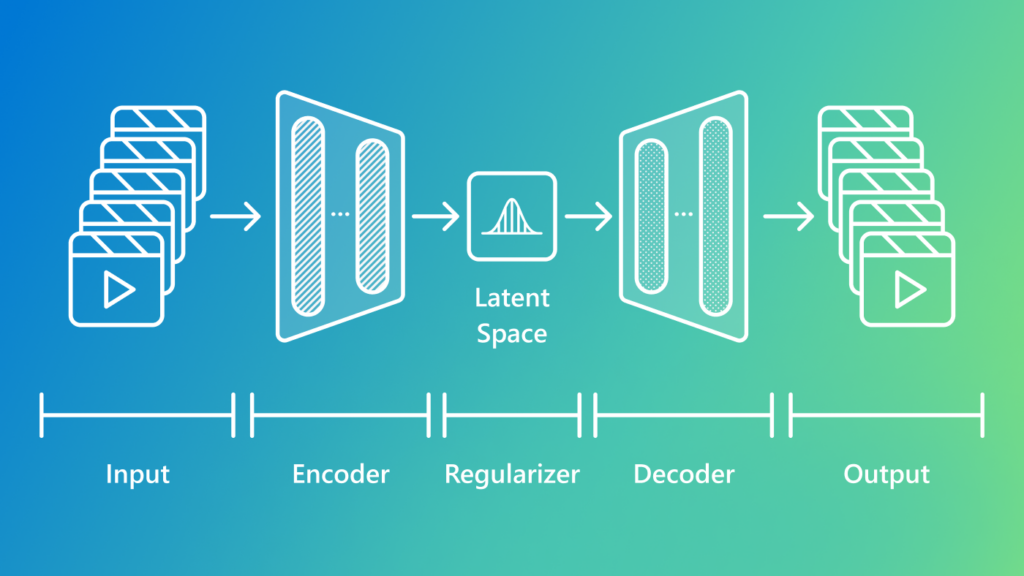
In this post, we explore the emerging techniques in token-efficient long video understanding for multimodal LLMs. We break down the challenges, recent architectural innovations, and practical strategies that enable scalable, high-fidelity video comprehension within the constraints of modern transformers.
Why Long Video Understanding is Hard
Long videos, by their nature, contain thousands of frames, each potentially carrying rich visual and audio information. To make sense of these sequences:
-
Frame sampling must preserve key semantic events.
-
Temporal alignment with text, speech, or actions must be maintained.
-
Multimodal fusion needs to be efficient yet context-aware.
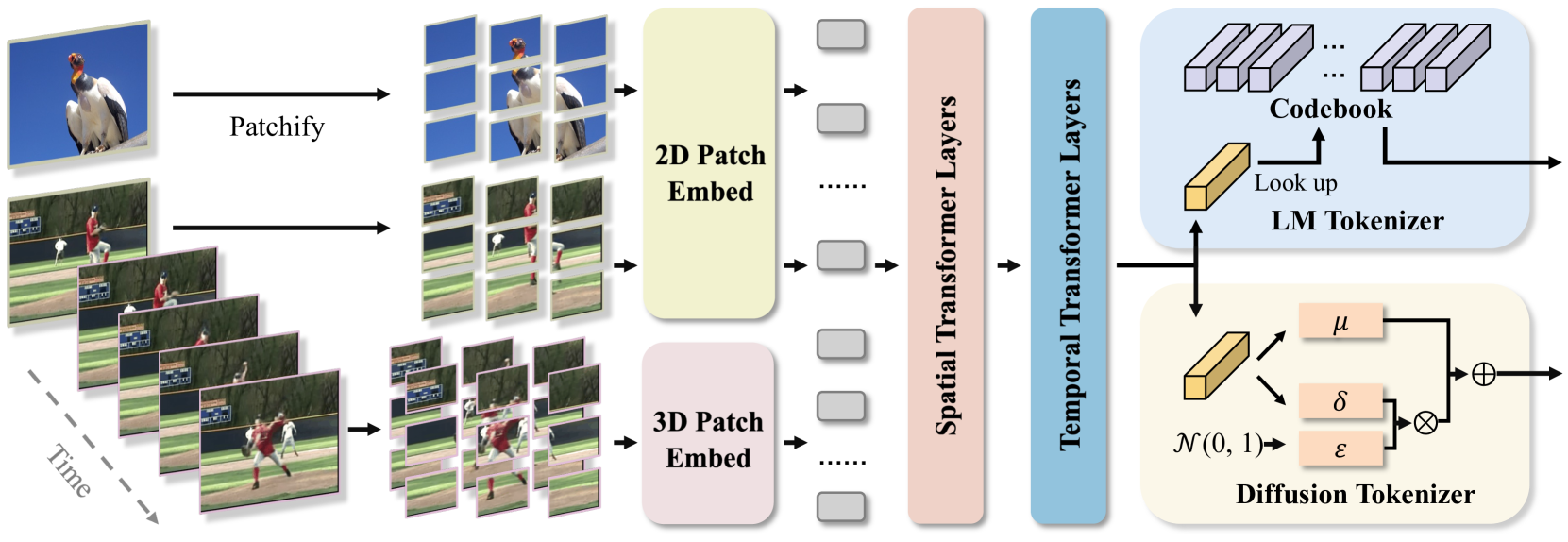
But here’s the catch: Most transformer-based models have a fixed or quadratic complexity with sequence length. Encoding every frame naively as image patches (e.g., via ViT or CLIP) quickly blows past the 4K–16K token limits most LLMs can handle.
So how can we compress or distill this information without losing critical context?
The Rise of Token-Efficient Architectures
Recent work has introduced innovative solutions that trade off token count for representational power. Let’s look at a few:
1. Temporal Compression Modules
One of the most successful techniques involves temporal compression layers that reduce frame-level redundancy. These modules:
-
Aggregate temporally nearby frames.
-
Preserve motion cues and scene changes.
-
Output a condensed token stream suitable for transformer processing.
Think of it like a temporal attention pooling system—akin to max pooling in CNNs, but for time-based sequences.
2. Perceiver and Perceiver IO
Google’s Perceiver architecture introduced a latent bottleneck that allows massive inputs (up to 1M tokens) to be projected into a smaller latent space via cross-attention. This is especially useful for video, where raw pixels can be efficiently abstracted into latent representations.
3. Segment-Aware Encoding
Instead of sampling fixed-rate frames, segment-aware methods use scene detection or activity segmentation to adaptively tokenize more densely around important actions. This allows higher fidelity where it matters (e.g., a sports highlight or gesture) and sparser representation elsewhere.
4. Multiscale Tokenization
Hierarchical encoding strategies inspired by vision transformers can apply different resolutions for coarse vs. fine-grained understanding. For instance:
-
Use low-resolution embeddings for scene-level context.
-
Use high-resolution tokens only for temporally sparse keyframes.
Integrating with Multimodal LLMs
Multimodal LLMs like GPT-4o, Flamingo, Video-LLaVA, and MM1 are being trained to natively handle sequences of visual, audio, and textual inputs. However, even these powerful models are sensitive to input token budgets.
Token-efficient strategies help:
-
Extend temporal window: Analyze longer sequences without hitting token limits.
-
Preserve multimodal alignment: Avoid dropping context-critical audio/visual cues.
-
Enable low-latency inference: Ideal for real-time applications like autonomous agents, video chat summarization, and smart surveillance.
Real-World Applications
Here are a few practical use cases enabled by token-efficient long video understanding:
-
Surveillance summarization: Extract key events from hours of CCTV footage in a few seconds.
-
Meeting/video call understanding: Summarize 1-hour Zoom recordings with multimodal context (who spoke, what was shared, when).
-
Sports analytics: Break down game footage to identify key plays or athlete actions.
-
Educational content summarization: Automatically index and summarize long lectures or tutorials.
-
Interactive agents: Create agents that can “watch” videos and answer questions about them.
Future Directions
The field is still rapidly evolving. Here are a few open areas of research:
-
End-to-end differentiable compression: Can we learn token-efficient representations directly during model training?
-
Memory-augmented models: How can external memory extend context beyond current token limits?
-
Joint audio-visual temporal compression: Most methods compress modalities independently—can we align them better?
-
Fine-grained reasoning over compressed tokens: How can models perform spatial-temporal reasoning with fewer tokens?
Conclusion
Token-efficient long video understanding is unlocking the next frontier of truly multimodal AI. By compressing visual and temporal information into smart, learnable representations, we can finally bring the power of LLMs to video at scale.
As hardware evolves and model architectures become more efficient, expect to see even longer, richer, real-time video comprehension become not just possible—but mainstream.
If you’re building a system that needs to watch, listen, and understand long-form video—start thinking about token efficiency as a first-class design constraint.
Want to go deeper? I’ll soon be releasing a practical walkthrough using Video-LLaVA, CLIP, and Token Merging with real-time streaming video input. subscribe to the newsletter.



